

Why Your Best Detection Tool Is Critical Thinking

Every year the stack grows: a new sensor, a new dashboard, a new detection pack, a new box that promises to catch what the last one missed. The EDR. The SIEM. An NDR. The SOAR platform. The ticketing system. Two or three threat-intel feeds.
The detections get faster. The dashboards get denser. And every year, analysts still miss things. Not because a tool failed. Because the thinking did.
We borrowed the words
Look at the language the industry runs on. Almost none of it is ours. War games come from Prussian Kriegsspiel. Triage from Napoleonic battlefield medicine. Kill chain from US Air Force targeting doctrine. OPSEC from a Vietnam-era operation. OSINT, red team, blue team, TTPs. We took the military's operational vocabulary wholesale, and we took some of its frameworks with it: the kill chain, the threat models, the exercises.
There is one thing we did not take. The discipline underneath the words: how their analysts learned to think.
The intelligence community spent generations on exactly that problem, why smart analysts make bad calls, and what to do about it. They wrote it down. Richards Heuer’s Psychology of Intelligence Analysis came out of the CIA in 1999. David T. Moore’s Critical Thinking and Intelligence Analysis came out of the National Defense Intelligence College. Both are public. Both are free.
We borrowed the words. We did not borrow the discipline. The gap is not in the stack. It is in how we read what the stack shows us.
Monday morning
It is Monday morning. The queue is full and it is not getting shorter.
You open the first alert. EDR-2026-04822. Severity medium. A developer workstation on the engineering subnet, the user signed in, business hours. Three commands in a single burst:
whoami
net group "Domain Admins" /domain
nltest /domain_trustsParent process is the interactive shell. No outbound traffic before or after. The EDR verdict is low confidence: recon-like, but probably an admin script or someone poking around.
You have seen this five times this month. Active session, known user, normal hours, nothing following it. It looks routine. Your cursor is already on the close button.
Routine false positive at thirty seconds or a missed breach uncovered in thirty days.
Here is the same alert, walked through one investigation template. Five sections, the telemetry you were about to dismiss.
Section 1 - Intake
Before you read the alert as a story, you fill in six cells. Five W's and an H, borrowed from journalism and formalized by police and intelligence services.

The cell that carries the weight is WHO. Not “the developer.” A session originating from the developer’s workstation. Those are two different things. The first phrasing smuggles in a trusted human and quietly decides which evidence will feel relevant later. The second leaves the question open. That single word is where anchoring loses its grip.
The rest fall into place once the framing is honest. WHAT is domain reconnaissance, the textbook shape of account and trust enumeration. WHERE is an engineering workstation, a tier that has no business mapping Domain Admins. WHY has no plausible answer for a developer mid-sprint. HOW looks like a human at a keyboard, which is a fact to hold, not a conclusion to trust.
Section 2 - Hypotheses
The fastest way to confirm what you already believe is to carry a hypothesis.
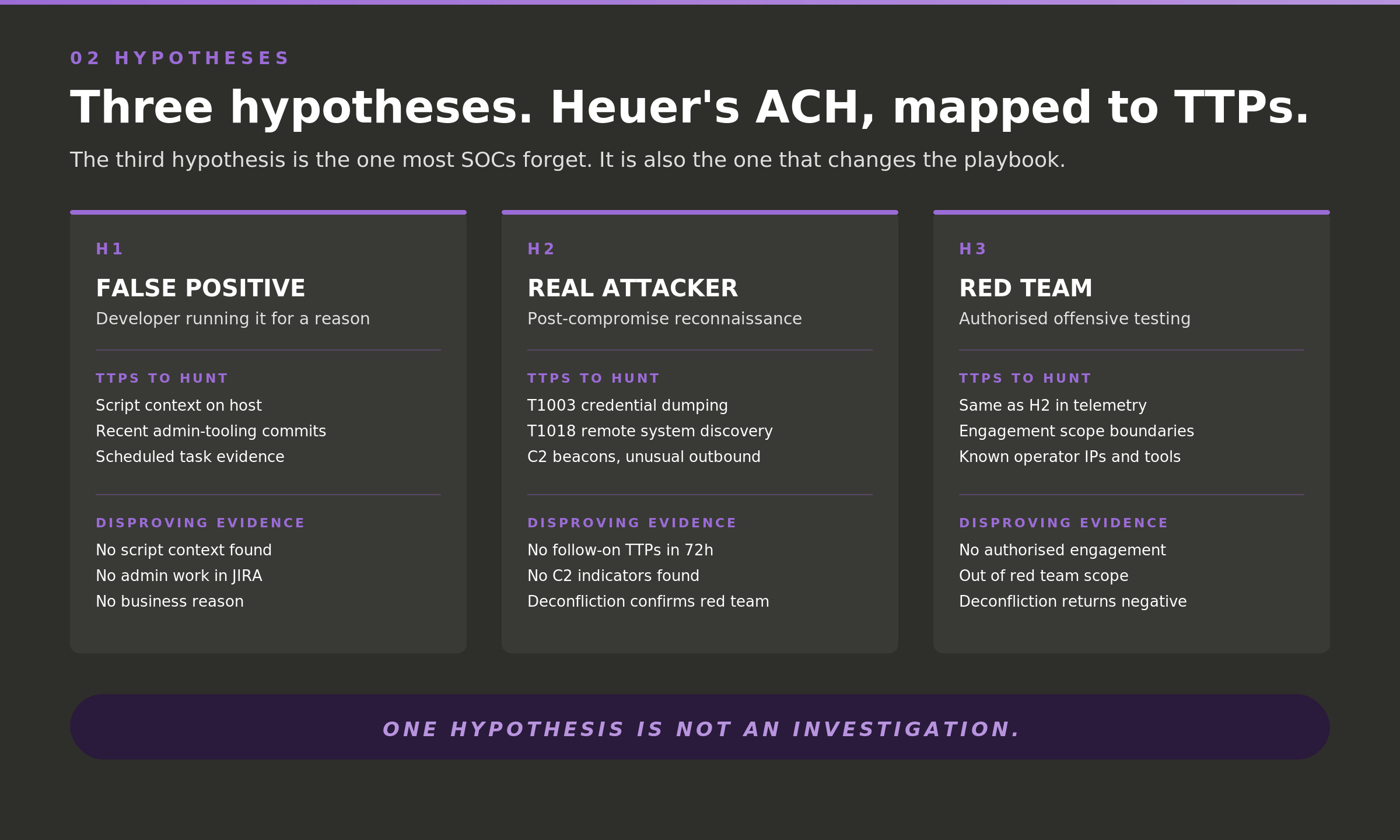
This is Analysis of Competing Hypotheses, Heuer’s method. The rule is at least two, better three. H1, a developer with a reason. H2, a real attacker operating through the live session. H3, an authorised red team that is functionally identical to H2 in the telemetry and completely different in the response it demands.
The third hypothesis is the one most queues never write down, and it is the one that decides whether the next hour is incident response or a phone call. Rank the three by the evidence that would disprove them, not the evidence that would confirm them. One hypothesis is not an investigation. It is a guess with paperwork.
Section 3 - Evidence
Evidence has two moves, and the order matters. First you assemble. Then you weigh.
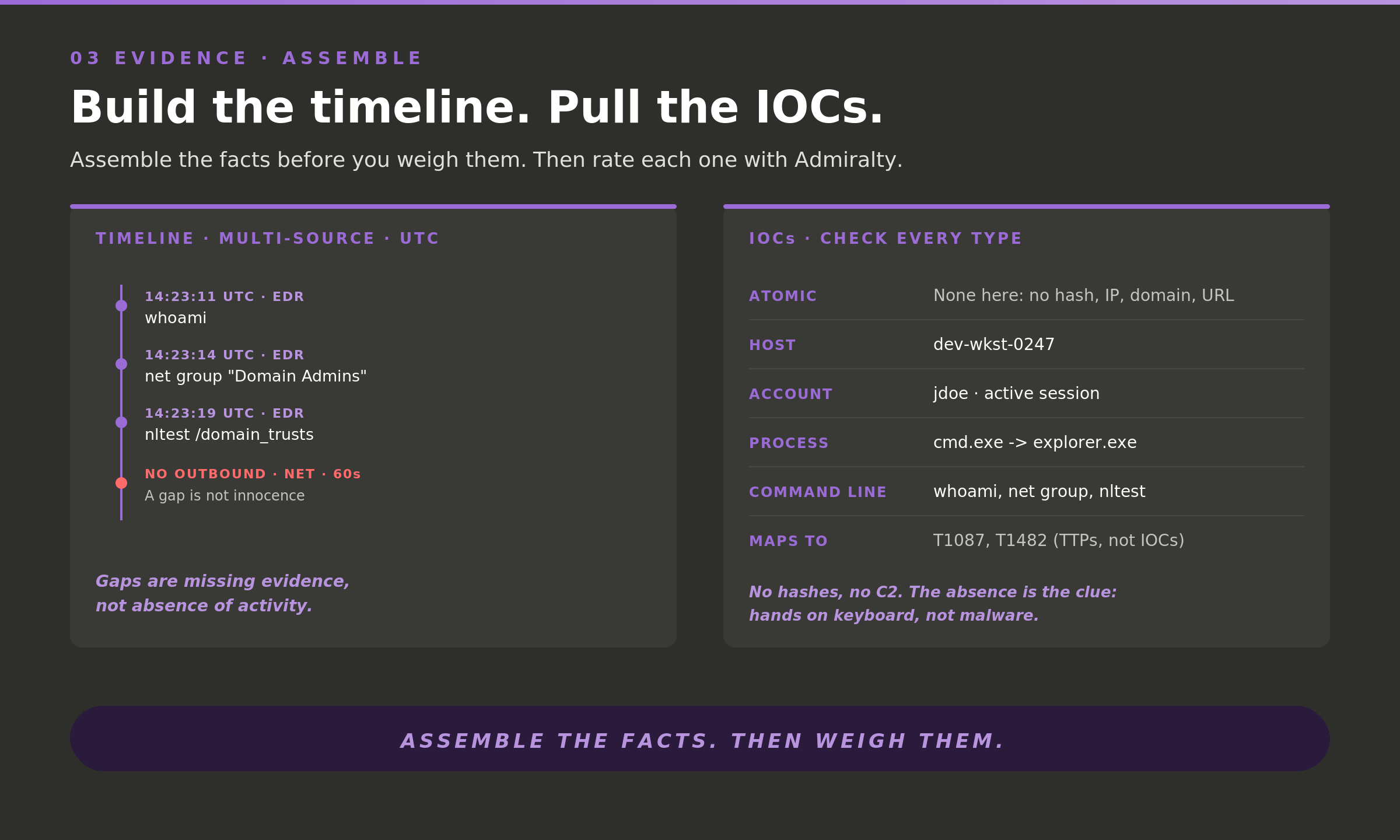
Assembling means a multi-source timeline in UTC and a typed list of indicators. On this alert the timeline is short and the indicator list is thin. No hashes. No command-and-control. No file written to disk. That emptiness is not nothing. The absence of atomic indicators is itself a finding: this looks like hands on a keyboard, not malware on a host. A sixty-second gap with no outbound traffic is not innocence. Attackers and red teams both pause between recon and the next stage.
Then you weigh. Every piece of evidence carries a rating.

The Admiralty Code is a NATO standard, two characters: a letter for how reliable the source is and a number for how credible the information is. Most analysts have never seen it, and it is the cleanest defence against confirmation bias I know.
Rate the case. The user says they did not run those commands. That is a fairly reliable person making an unverified claim about one specific session: C3, not A1. The session telemetry shows the account logged in, which says the session is open, not that the human is at the keyboard: B2. The network silence is definitive log data supporting a doubtful inference: A4. Three pieces of evidence, and not one of them rates above C3 toward the benign story. The hypothesis you wanted to pick is not earning its weight. The point of the rating is that it makes you say so out loud.
Section 4 - Adversarial Review
The brain that built the bias cannot detect it alone. So you attack your own analysis before someone else does.

Start with the bias checklist: keep the actor’s name out of the ticket until evidence supports it, check the base rate for your environment, ask what you would conclude without the tool. Then put the story in front of a devil’s advocate, someone whose only job is to break it. That can be a team member, an LLM, or you after a short break with fresh eyes.
One move decides this case. Deconfliction rules out friendly fire. A single question to the security manager: is anyone authorized running offensive testing in this environment right now. The answer sorts an incident from a learning conversation, and skipping it is how teams either burn response ressources on their own red team or close on a real intruder. The pre-mortem comes last, a final stress-test: assume the analysis was wrong and write what you missed before you commit.
Section 5 - Decision
Analysis that does not move is a diary entry. The decision is a loop, not a checkbox.
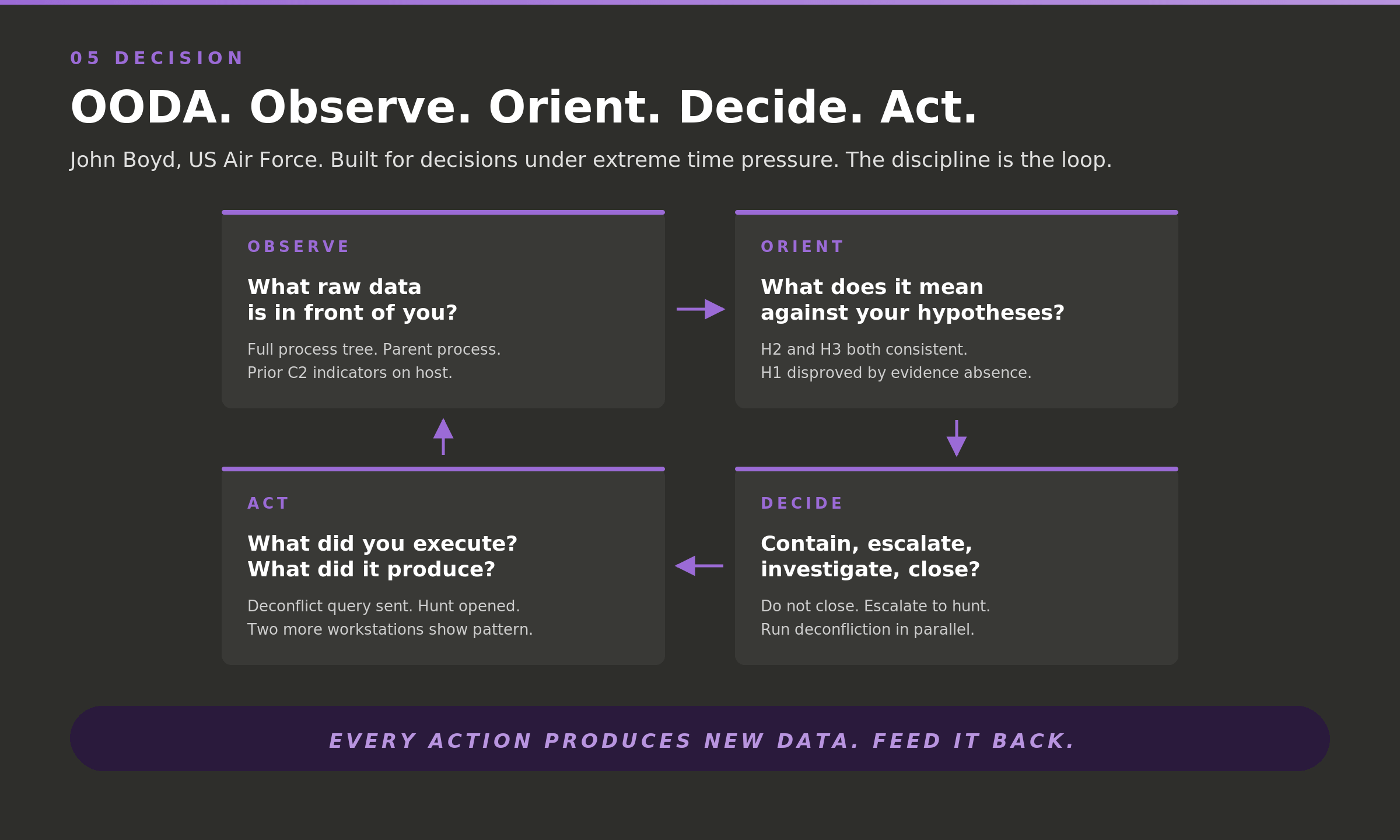
John Boyd built the OODA loop for fighter pilots deciding under fire. Observe pulls the full process tree and prior host activity. Orient places it against the three hypotheses: H2 and H3 both hold, H1 does not. Decide is not "close." It is escalate to a hunt and run deconfliction in parallel. Act executes both. Then the loop turns, because the act produced new data: the hunt finds two more workstations running the same recon pattern inside forty-eight hours. One event was an anomaly. Three is a campaign.
The reveal
Deconfliction comes back. There was an authorized, no-notice red team running that month. Initial access was a spearphish to a finance employee two weeks earlier. The developer workstation was the third stop in their lateral movement and they were heading for the Tier Zero tier.
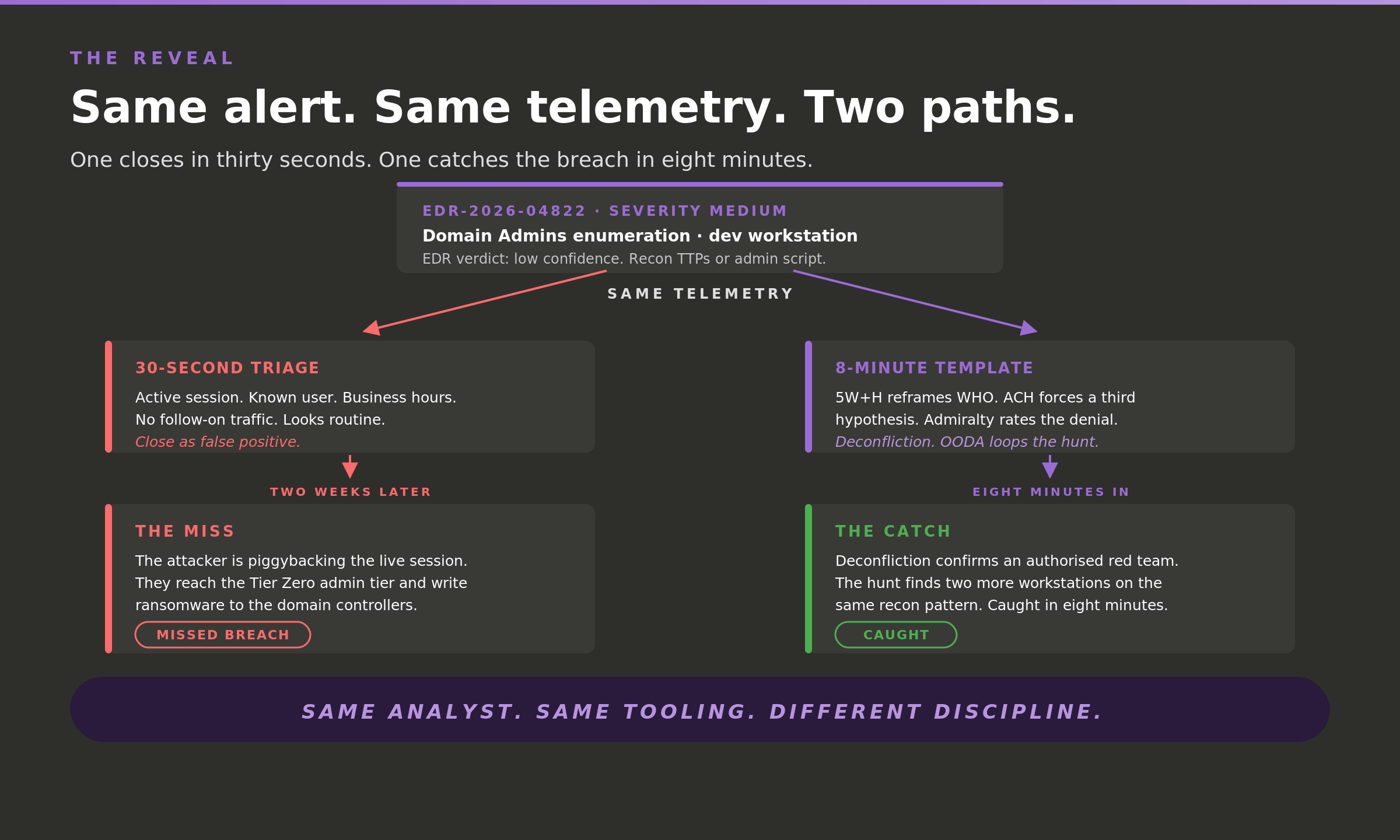
Same telemetry as a real attacker, same urgency and same TTPs.
Different attribution:
Closed as a false positive, this is a missed breach. The red team writes a friendly debrief. A real adversary deploys ransomware to your environment.
Same analyst, Same tooling but different discipline. Eight minutes from the alert you could have closed to an escalation. The only thing that changed was the order of your thinking.
The full walk is one page
Five sections, one artifact. The filled template is the handover: the next analyst inherits your reasoning, not just your verdict.

Triage is not investigation
Everything above is an investigation. Most of your day may not.
When the queue is full and you have minutes per alert, you are triaging, not investigating. Triage is the decision of which alerts earn the full template and which do not. It is a different job, and it has its own version of the discipline.

Three questions. What is my primary hypothesis right now. How would I rate my strongest piece of evidence on Admiralty. What single thing would change my mind. A couple minutes per alert, run on the queue, not on a single case. Not every alert is a case. Triage is how you find the one that is.
The work is already done
The intelligence community already figured out why good analysts make bad calls. They wrote it up and gave it away.
If you have followed this series, you have been collecting the pieces. The four biases. The two systems. The W + H questions. Each post was one tool. This is the piece where they live together in a single page you can run on a real shift.
We do not have to redo it. We borrowed the words. Now borrow the discipline.
What is on the horizon
The next version of this problem is already coming. AI writes the first-draft triage now, fluent and confident and sometimes wrong, the job is shifting from producing the analysis to judging the machine's analysis. An LLM verdict starts unverified, the same as any other source. The discipline that rates a person's claim is the discipline that rates the model's.
Appendix: The Investigation Template
Copy this into your notes app, your ticketing system, or a markdown file. It is a living document. Fill it as the investigation moves.
# Investigation Template
*Companion artefact to "Why Your Best Detection Tool Is Critical Thinking"*
---
## Case Header
- **TLP Classification:** [ ] RED [ ] AMBER+STRICT [ ] AMBER [ ] GREEN [ ] CLEAR
- **Case ID:**
- **Analyst:**
- **Opened (UTC):**
- **Status:** [ ] Open [ ] Escalated [ ] Closed
---
## Timeline (UTC, Multi-Source)
| Timestamp (UTC) | Source | Event Description |
|------------------|--------|-------------------|
| YYYY-MM-DD HH:MM | | |
| YYYY-MM-DD HH:MM | | |
| YYYY-MM-DD HH:MM | | |
| YYYY-MM-DD HH:MM | | |
> Mark timezone differences explicitly. Look for gaps. Hours with no log data indicate often missing evidence, not absence of activity.
---
## Section 1 - Intake (5W+H)
*Goal: structured first read of the alert before pattern-matching kicks in.*
| Question | Response |
|----------|----------|
| **WHO** | Victim(s), suspected actor(s), beneficiaries |
| **WHAT** | Exactly what happened, in one sentence |
| **WHEN** | First observed AND earliest indicator (UTC) |
| **WHERE**| Systems, networks, geography |
| **WHY** | Likely motive: ransom, espionage, sabotage, profit |
| **HOW** | Initial access vector and kill-chain stage so far |
---
## Section 2 - Hypotheses (ACH + TTPs)
*Goal: force at least two hypotheses. One hypothesis is not an investigation.*
### Hypothesis 1 (Primary)
- **Description:**
- **Confidence:** [ ] HIGH (70-100%) [ ] MEDIUM (40-70%) [ ] LOW (1-40%)
- **TTPs to hunt for:**
- **Disproving evidence would be:**
### Hypothesis 2 (Alternative)
- **Description:**
- **Confidence:** [ ] HIGH [ ] MEDIUM [ ] LOW
- **TTPs to hunt for:**
- **Disproving evidence would be:**
### Hypothesis 3 (Optional: Insider / Red Team / Supply Chain / Benign)
- **Description:**
- **Confidence:** [ ] HIGH [ ] MEDIUM [ ] LOW
- **TTPs to hunt for:**
- **Disproving evidence would be:**
> Rank hypotheses by which has the most disconfirming evidence, not the most confirming evidence. Heuer, Analysis of Competing Hypotheses.
---
## Section 3 - Evidence (Admiralty Scored)
*Goal: every piece of evidence carries a credibility rating. Unrated evidence gets a free pass it has not earned.*
| Type | Indicator | Admiralty | TTPs | Notes |
|------|-----------|-----------|------|-------|
| Hash | | | | |
| IP | | | | |
| Domain | | | | |
| URL | | | | |
| File Path | | | | |
| Other | | | | |
**Admiralty Code reference:**
- **Source reliability (A-F):** A = Completely reliable, B = Usually reliable, C = Fairly reliable, D = Not usually reliable, E = Unreliable, F = Cannot be judged
- **Information credibility (1-6):** 1 = Confirmed by other sources, 2 = Probably true, 3 = Possibly true, 4 = Doubtful, 5 = Improbable, 6 = Cannot be judged
> Example: B2 = Usually reliable source, probably true. LLM output on framed indicators starts at F6 until verified by independent evidence.
---
## Section 4 - Adversarial Review
*Goal: actively try to break your own analysis before someone else does.*
### Bias Checklist
- [ ] **Anchoring defence:** Actor / malware name banned from ticket until evidence supports it
- [ ] **Tool verdicts manually verified:** What would I conclude without the tool?
- [ ] **Base-rate check:** Is this common in OUR environment?
- [ ] **Null hypothesis considered:** Could this be benign?
### Devil's Advocate
> Someone whose only job is to break the primary hypothesis. Not for approval, for disagreement. It can be a team member, an LLM, or yourself after a short break.
**Who or what challenged it:**
### Information Gaps
- [ ] Missing log sources?
- [ ] Unchecked systems?
- [ ] Unverified IOCs?
- [ ] Memory not captured?
- [ ] **What single piece of evidence would change your primary hypothesis?**
- [ ] Other:
### Pre-mortem
> Imagine it is six months from now and this analysis was wrong. What did we miss? Write the postmortem before the incident.
**Response:**
---
## Section 5 - Decision (OODA)
*Goal: turn analysis into action and feed the result back into analysis. The loop runs until the case closes.*
| Phase | Question | Response |
|---|---|---|
| **OBSERVE** | What raw data is in front of you right now? | |
| **ORIENT** | What does it mean given your context and current hypotheses? | |
| **DECIDE** | Contain, escalate, investigate further, close? | |
| **ACT** | What did you execute, with what authority, with what outcome? | |
> Every action produces new data. Feed it back to OBSERVE. The loop runs continuously until the case is closed and handed over.
### Under-pressure version (5-minute triage)
When you do not have time for the full template, you are triaging, not investigating. The OODA loop collapses to three questions:
1. **What is my primary hypothesis right now?**
2. **How would I rate the strongest evidence on Admiralty?**
3. **What single thing would change my mind?**
Decide. Act. Loop.
---
## Overall Case Confidence
**Confidence in hypothesis:** [ ] HIGH (70-100%) [ ] MEDIUM (40-70%) [ ] LOW (1-40%)
**Justification (2-3 sentences):**
- What evidence supports this confidence level?
- What evidence still has gaps?
- Which assumption, if wrong, would drop your confidence by one level?
---
**Analyst:** ___________________ **Date:** ___________________ **Case ID:** ___________________
> The filled template IS the handover. The next analyst inherits your thinking, not just your conclusions. Write it so they can pick up the case without asking you a question.